
Cake or Death?
A month since the EU cookie rules came into force, Milena Popova looks at the good, the bad and the complete misses in ‘consent’ implementation, and some helpful tips on managing your cookies.

At the end of May this year, new EU rules on cookies came into force. We are not talking the chocolate chip variety here, but the small chunks of seemingly-random text which websites save on your computer as you browse the web. These little files enable basic functionalities like online shopping or setting your language preferences, but they can also be used to identify you and track your browsing across multiple sites. This allows, for instance, advertisers to build up detailed profiles of your interests and behaviour to better target their ads. Most internet users are only vaguely aware of cookies, what they do or how they work.
The new rules are part of the EU e-Privacy directive, which members states needed to implement into national law by May 2011. Most member states failed to meet the deadline and are still lagging behind. The UK implemented the Directive in time but then gave website owners a year to ensure compliance with the new regulations. Since May 26th this year, however, UK websites have to obtain their users’ consent before they set cookies on their devices. The original guidance was that consent had to be actively given (e.g. by ticking a box), which led to some very frantic action and widespread predictions of a cookiepocalypse in the tech industry in the weeks leading up to the implementation deadline. Then, at the last minute, the Information Commissioner’s Office updated its guidance to state that “implied consent” was an acceptable option in some, if not most, cases.
So a month into the cookiepocalypse, what’s the state of play? Certainly for the first couple of weeks I found it quite easy to keep a mental tally of how many websites were even attempting to comply with the new legislation. The first site I spotted doing to was Yes Scotland, the campaign for a yes vote in the upcoming Scottish independence referendum. There is a warning triangle in the bottom right-hand corner of the screen which takes you to their privacy policy. That then explains what cookies are and how to turn them off in your browser settings if you want to. The implementation is ugly, but you’ve got to give them credit for trying.

Over the last week or so I’ve seen more and more sites trying to comply, to the point where I have now stopped counting. This is a good thing, though how these sites have chosen to implement cookie compliance is less good. Most seem to be going for the “implied consent” - or what I call a “cake or death” approach. Here’s an example from the Guardian:

The “Find out more” link does take you to a more detailed explanation and, again, instructions on how to turn cookies off in your browser, but at first glance this is very much an “if you don’t like it you don’t have to read our site” situation.
The Information Commissioner’s Office website is slightly better in this regard, in that it asks you to actively tick a box accepting cookies before it will set any on your device:
The downside of course is that if you don’t consent to their cookies, the box stays at the top of the page forever - not a huge issue on a decent-sized screen but on a netbook, tablet or mobile this is annoying.
A couple of implementations I’ve seen have bordered on the farcical, including the “If you don’t accept cookies, please let us set a cookie to say so” approach (which does avoid the persistent box at the top of the screen problem) and the Information Commissioner’s very own cookie guidance video which comes with the warning that “playing YouTube videos sets a cookie”. Informed consent this is not.
My favourite approach so far comes from Toyota UK. They split cookies into three different categories (vaguely corresponding to the four categories used by the EU), provide clear explanations of what they are used for, and allow you to individually turn each category on or off. Have a cookie, Toyota:
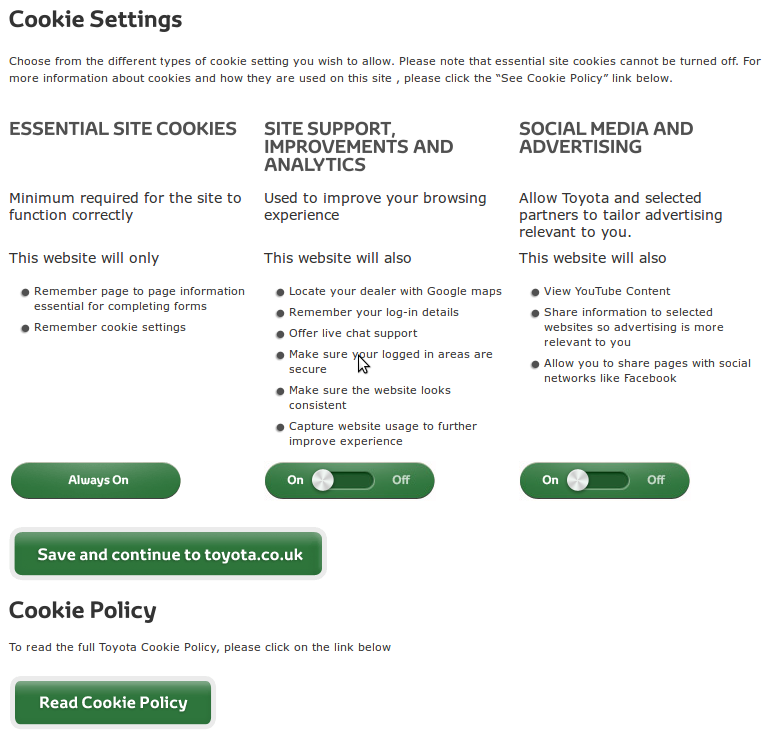
If at this point it’s all becoming a bit much and you just want to go and consume some baked goods, here are just a couple of final thoughts and tips. I do think that the new cookie rules are raising awareness of the issue among the general public. Even if a lot of people aren’t bothering to click the “find out more” links, some are, and explanations are now written in much more understandable language. Where explicit consent is required (e.g. the ICO’s website), early evidence suggests that most people prefer to opt out of cookies. These are very positive developments for individuals’ privacy, although of course we could always do better.
If you are concerned about cookies and trackers, there are a few things you can do. Learn to control the cookie settings on your browser - the Guardian’s website has links to instructions for most common browsers. You can also find out who’s is tracking your browsing and how. If you’re using Firefox, the Collusion add-on will help you track the trackers and build up a picture of who knows what about you. Additionally, Ghostery can help you block cookies and trackers you don’t want. So even if most websites are behind on complying with the law, there are plenty of easy-to-use tools at your disposal to regain control of your privacy.
Milena is an economics & politics graduate, an IT manager, and a campaigner for digital rights, electoral reform and women's rights. She is also a member of ORG's board and continues to write for the ORGzine in a personal capacity. She tweets as @elmyra
Image: CC-BY-ND 2.0 Flickr: Kari C
How to use the Curator's Code
Ruth Coustick explains how the Curator's Code works and the intentions and ideas behind it.

Following my trail of image-centred blog reading I have recently come across the Curator's Code. (In the spirit of this invention I would like to hat-tip Off Beat Empire before I continue). Maria Popova, writer of brainpickings.org is:
"doing for attribution of discovery what Creative Commons has done for image attribution "
Creative Commons, whilst allowing re-mixing and re-distribution of data, recognises the need to credit the original source. The Curator's Code credits the person who does the re-distributing as well. As the site says:
"In an age of information overload, information discovery — the service of bringing to the public’s attention that which is interesting, meaningful, important, and otherwise worthy of our time and thought — is a form of creative and intellectual labor, and one of increasing importance and urgency. A form of authorship, if you will."
The point being that it is not just the artist, but the museum curator who deserves some recognition. So let's just explain how this works. They have introduced two little symbols for everyday use when attributing sources.
"The system is based on two basic types of attribution, each shorthanded by a special unicode character, much like ™ for “trademark” and for © “copyright.” And while the symbols are a cleaner way to do it, you may still choose to credit the “old-fashioned” way, using “via” and “HT”"
Symbol 1.
ᔥstands for via -This is for direct discovery
Symbol 2
↬stands for hat tip -This is for work you have edited or expanded upon
To give an example: if you want to post an image of cat in a hammock you can attribute the site you found it on catsinhammocks.com and the original photographer SelenaKyle01 on Flickr like this:
↬Cats in Hammocks | ᔥ SelinaKyle01 Flickr
This example is sadly entirely made up. The symbols/codes are available as an 'Attribute!' button on your bookmark bar, which is how I am using them now. If you want further explanation please visit both the Curator's Code site and brain pickings which has much detail about how it all works, how to download the bookmarklet and some great design. The message here is not simply about how to credit, but to credit.
As a blogger I am keen to spread the use of these unicodes amongst the Web. However, as she comments, the symbols don't matter quite so much as the discussion and the intent. Following on from my recent article on Kickstarter as the eRenaissance, what also interests me is the attitude and the terminology of honour codes involved:
"This not about policing the Internet from a place of top-down authority, it’s about encouraging respect and kindness among the community. "
Recently I was introduced to the free speech debate website which promotes a set of codes for behaviour and free speech on the internet. I have listed the first 3 of these below, but would recommend delving into the site for the rest.
1.We – all human beings – must be free and able to express ourselves, and to receive and impart information and ideas, regardless of frontiers.
2.We defend the internet and all other forms of communication against illegitimate encroachments by both public and private powers.
3.We require and create open, diverse media so we can make well-informed decisions and participate fully in political life.
These two separate sites have something in common with each other. Across the internet there is a spread of ideas about protecting the artists and human rights with 'codes' rather 'acts'. Pretty much every forum I have participated in has had its own code of behaviour. Sometimes these are very specific to that discussion topic "always give spoiler warnings" / "trigger warnings", depending on my digital location, but there is always a general understanding of "Be nice" in our discussions. Yet, governments are attempting to codify the rolling and shifting landscape of the internet with unpopular rhyming laws: ACTA, SOPA, COPA, but the Curator's Code and the 10 principles for global free speech address similar problems through a polite call to self-regulation.
It's not just "don't be evil". It is "be honourable". And if I can feel like people on the Internet can be knights, not trolls, then I am happy.
All quotations are taken from brainpickings with permission of the author.
Image: Site designed by Kelli Anderson
How-to: Creative Commons
A guide to “copyleft” and using Creative Commons licenses to both protect and share your work in the digital age

Have you heard of Creative Commons (CC)? Well, you’ve almost certainly benefited from it.
When was the last time you read something on Wikipedia? The vast majority of content on Wikipedia is under a Creative Commons license, which is what makes it legal for you to use the material, copy it, distribute it, build on it, and do pretty much whatever else you can think of with it – within certain guidelines.
Creative Commons is a nonprofit organisation with an incredibly ambitious and inspiring vision: “Realizing the full potential of the Internet – universal access to research, education, full participation in culture, and driving a new era of development, growth, and productivity.”
It describes its activities as “developing, supporting, and stewarding legal and technical infrastructure that maximises digital creativity, sharing and innovation.”
The philosophy at the root of CC is simple: our culture and our creativity do not exist in isolation from the past, or from our contemporaries. Every time we create something, we stand on the shoulders of giants who have gone before us. Culture is a conversation, not a monologue, and in order for us to create, we need to have access to creations from the past. We need to be able to use them, copy them, remix them. This is not just true in the arts – it applies just as much to the sciences, to education, to any form of human creativity.
Think of your favourite book: chances are, somewhere in it is a reference or a quote from another work, be it a song, a movie, or another book. Think of scientific discoveries: they don’t happen in a vacuum - scientists constantly build on each other’s work. Think of composers who set texts to music; of being inspired by a picture to write a poem; of the constant conversation that is social media and the blogosphere.
Now imagine a world where to use anything that another person has created, you need their permission. It’s not a world that different from ours actually. And certainly before Creative Commons was established, creators didn’t have much of a choice: they could release their work into the public domain or they could retain full copyright (all rights reserved). But what if you were okay with people doing certain things with your work but not others? For instance, you didn’t mind them passing it on to their friends, but you’d really rather they didn’t change bits of it around. Well, tough – your best bet was retaining full copyright and then granting people permission on a case-by-case basis. Just the fact that they have to ask puts most people off in the first place, and even so, you probably wouldn’t be able to cope with all the admin.
The Creative Commons legal framework enables you to fine-tune what rights over your work you wish to reserve and what rights you want to waive – or give away. By answering a few simple questions, you can get yourself a CC license to use. If you want to go ahead and do that, here are some of the things you might want to think about:
- Are you happy for people to share and reproduce your work?
- Are you happy for people to build on your work (create derivatives)? This could include anything from performing it to remixing it and adding bits of their own to it.
- Are you happy for people to make money from your work?
- And finally, do you want people to “share alike” – pass on the work they’ve created which is based on yours only the same manner under a CC license?
Once you’ve put some thought into the above, you can go to the Creative Commons website and choose your license. Simple.
So what funky things do people do with CC licenses? Well, Wikipedia is the obvious answer. But writers, artists and musicians are also increasingly making use of CC licensing. Science fiction author Cory Doctorow publishes all of his fiction under an Attribution-NonCommercial-ShareAlike license This means you can copy and share the work and creative derivatives, but you can’t make money out of it without asking Doctorow, and you need to share on the same terms. This means a lot more people get to enjoy Doctorow's work: fans and other artists have created audio-books, plays, podcasts, and even translated his work into languages in which official translations have not been published. Yet, Doctorow still makes money from selling hardcover books, official ebooks and official audiobooks. Indeed, it is plausible to assume that by making his work available for free under the CC license, he increases his exposure so much that he actually boosts sales.
Flickr also enables users to publish their photos under a CC license. For amateur photographers like myself, it’s a great means for exposure. I’ve had a couple of my pictures used in various things – the pinnacle being a LOLcat someone made out of a picture of my cat. Not only is it flattering that someone likes your photograph enough to want to use it, but, on the flipside, whenever you’re in need of an image, you can use Flickr. The site allows you to restrict the search function to only give you CC-licensed content, which saves you the hassle of having to find the rightsholder and ask for permission. Having said that, if you do use CC-licensed content, remember to always attribute it – and it’s always a nice gesture to drop a note to the author and let them know.
Some musicians release entire albums under CC licenses – the Nine Inch Nails’ album The Slip, for instance. Composers may also choose a CC license for their work, which enables musicians to perform it a lot more easily. The Magnatune record label also uses a CC license for its music, and users are actively encouraged to share up to three copies of music they've downloaded from Magnatune with their friends.
There are loads of other things available under the Creative Commons licenses – Wikipedia has a non-exhaustive list here, and it's always worth visiting the CC website itself and having a browse, or using the CC search engine.
Personally, I use the Attribution-Noncommercial-ShareAlike license for pretty much everything I release. I don't particularly want other people making money out of my work without at least asking – hence the noncommercial part. And I love the viral, slightly subversive quality of the ShareAlike condition; it lets me spread the joy of Creative Commons even further. So without further ado, go pick a license and start sharing!
Milena is an economics & politics graduate, an IT manager, and a campaigner for digital rights, electoral reform and women's rights. She blogs at milenapopova.eu and tweets as @elmyra

Latest Articles
Featured Article
Schmidt Happens

Wendy M. Grossman responds to "loopy" statements made by Google Executive Chairman Eric Schmidt in regards to censorship and encryption.
Find us on
ORGZine: the Digital Rights magazine written for and by Open Rights Group supporters and engaged experts expressing their personal views
People who have written us are: campaigners, inventors, legal professionals , artists, writers, curators and publishers, technology experts, volunteers, think tanks, MPs, journalists and ORG supporters.
